Hortonworks bills itself as a pure open source play version of Hadoop, both in terms of what it distributes and how it invests resources back into Hadoop's core projects. In a blog post today, Hortonworks announced plans to plow its resources back into Spark, the Hadoop streamed-data, machine-learning, and in-memory data processing system.
In
the post, Hortonworks says it has "outlined a set of initiatives to
address some of the current challenges with the technology that will
make it easier for users to consume as part of the completely open
source Hortonworks Data Platform."
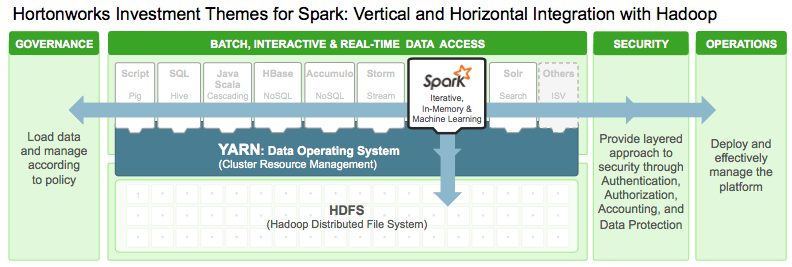
The task falls in two basic categories. First is more deeply integrating Spark with YARN, the technology created to replace MapReduce so that Hadoop applications can run more efficiently in parallel. Spark runs on YARN,
but this "leads to a less than ideal utilization of cluster resources"
in the current version of Spark, according to Hortonworks, "particularly
when large datasets are involved."
Spark's big selling point is
in-memory processing, so the planned work involves Spark's use of
memory-handling features built into YARN. One such feature is node
labels, which allows Spark applications to be tagged, so they can be
automatically processed on nodes in the cluster where memory is in
abundance.
Spark provides in-memory and real-time processing for Hadoop. It
works with the YARN framework, but its integration with YARN is
rudimentary. The other major category of improvement covers
general Hadoop issues: security, governance, and operations. Security on
Hadoop has been catch-as-catch-can for much of the product's lifetime,
but a new Apache project that entered incubation earlier this year -- Apache Argus -- addresses it in a consistent manner.
Argus did not start as a community initiative; it's the open-sourced version of a commercial product, XA Secure, that Hortonworks acquired and transformed into an Apache-hosted project. The idea, as Hortonworks explained earlier this year, is to provide a centralized way to define and enforce security policy
across Hadoop and all its components. This includes access controls
down to the folder and file level in HDFS, and to the table and column
level in Hive and HBase. But don't expect automatic Argus integration --
this project has a long road ahead for Hortonworks and everyone else
contributing to the Hadoop ecosystem.
Other improvements include
better debugging facilities for apps that use Spark, and integration
with a YARN feature called ATS (Application Timeline Server). ATS
metrics can be used for further debugging and performance improvements
of Spark apps.
Spark is hardly the only in-memory processing
solution offered for Hadoop, although much of the competition is
proprietary. Pivotal, for instance, has an in-memory analytics system,
Gemfire XD, that recently upgraded to a new version.
It has some similarities with Spark, but it's aimed at those coming
from a traditional database background, and it's a closed source
offering. Cloudera has its own commercial distribution of Hadoop, albeit one that comes bundled with Spark instead of using a closed source substitute.
An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!







An impressive share, I just given this onto a colleague who was doing a little analysis on this. And he in fact bought me breakfast because I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to discuss this, I feel strongly about it and love reading more on this topic. If possible, as you become expertise, would you mind updating your blog with more details? It is highly helpful for me. Big thumb up for this blog post!
ReplyDeleteWebsite
Information