

All the energy about enormous information and the Hadoop biological system - yet so few undertaking activities worked out. Lifting the environment to the cloud changes everything
Undertakings don't appear to show signs of improvement at making sense of Hadoop, yet that hasn't prevented them from dumping regularly expanding heaps of money into it.
By Gartner's preparatory appraisals, 2016 spend on Hadoop disseminations came to $800 million, a 40 percent spike from 2015. Sadly, all that spending still just has 14 percent of ventures really detailing Hadoop arrangements, scarcely moving from 2015's 10 percent.
One brilliant spot: Hadoop organizations are progressively moving to the cloud, where they may have a superior possibility of accomplishment.
Everyone's doing the Hadoop thing
Before you protest "Hadoop," contending that it has been uprooted by Apache Spark or other huge information framework, you're correct. What's more, off-base.
That is, for this situation Gartner incorporates all "monetarily bundled and upheld versions of the open source Apache Hadoop-related ventures" in its meaning of "Hadoop." at the end of the day, while the old-school HDFS and MapReduce are incorporated into Gartner's definition, so are YARN, Pig, Hive, HBase, ZooKeeper, Avro, Flume, Kafka, Oozie, Parquet, Solr, Spark, and Sqoop.
In fact, as Gartner investigator Merv Adrian clarifies, "The overview is about enormous information ventures." Given how standard huge information has gotten to be in prevailing press, it is enticing to prepare to stun the world information Hadoop ventures had gone standard in appropriation. It would likewise not be right.
As Gartner outlines, ventures appear to be stuck in a consistent condition of experimentation with Hadoop, never fully ready to move into creation:
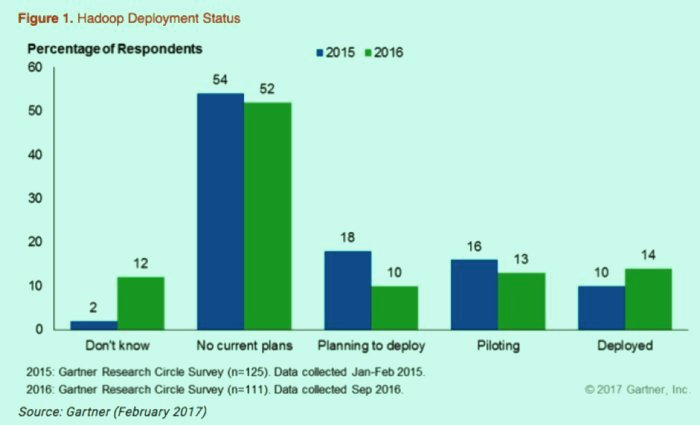
Not exclusively did 2016 see just a little increment in Hadoop arrangements, however the pipeline driving into organization fell no matter how you look at it. Regardless of the possibility that we expect that by one means or another "Hadoop" is skewing the outcomes and we have to dive into a more broad huge information definition, the memorable numbers aren't greatly improved:

(In total, enormous information has yielded huge buildup, yet not yet huge achievement. )
To the cloud!
All things considered, that is not exactly genuine. Hortonworks, for instance, as of late had a solid quarter, developing income 39 percent year over year. In 2016, the organization did about $200 million in income, $126 million of it got from memberships to its Hadoop stage.
Some portion of this accomplishment for Hortonworks, be that as it may, most likely descends to its expanding grasp of the cloud. As noted on its income call, around 25 percent of Hortonworks clients now run its product in general society cloud, up from roughly 0 percent two years prior. This is the place engineers need to run their product, and assuaging them is brilliant business.
While this move to the cloud likely supports Amazon Web Services and Microsoft Azure much more than it helps Hortonworks, Cloudera, or MapR, it's a rising tide that will tend to lift all vessels. It additionally may spare them from spilling.
One of the huge drivers for Hadoop organizations moving to the cloud is the sheer multifaceted nature of making Hadoop work. Consistently there's another Apache venture to supplement and quicken development in Hadoop, and it's by unimaginable for standard endeavors to keep up. For endeavors that aren't Google, staying aware of the most recent and most prominent in spilling examination, for instance, will "frequently require the utilization of youthful, unsupported programming," as Gartner notes.
Accordingly, Gartner says, "Cloud-based conveyance models likewise permit associations to better ingest the consistent stream of changes to the parts (regularly Apache ventures) in the Hadoop biological system." The truly difficult work of updating a steady stream of Hadoop segments is left to the cloud supplier, which additionally makes it simpler to deal with the partition of capacity and process.
In all honesty, this is the place huge information ventures have a place. As AWS item system boss Matt Wood let me know, "Those that go out and purchase costly framework find that the issue degree and space move truly rapidly. When they get around to noting the first question, the business has proceeded onward." at the end of the day, the cloud makes huge information reasonable, as well as makes it gainful.
What it may not do, as specified, is improve the customary Hadoop merchants over the long haul. Given that information will progressively live on open mists from Amazon, Microsoft, and Google, it's extremely conceivable that alleged information gravity will push ventures to utilize the Hadoop administrations local to those stages.




No comments:
Post a Comment